It would clearly be desirable that, if a client broadcasts a new command to all replicas, that it eventually receives at least one response. This is an example of a liveness property. It requires that if one or more commands have been proposed for a particular slot, that some command is eventually decided for that slot. Unfortunately, the Synod protocol as described does not guarantee this, even in the absence of any failure whatsoever. In fact, failures tend to be good for liveness. If all leaders but one fail, Paxos is guaranteed to terminate.
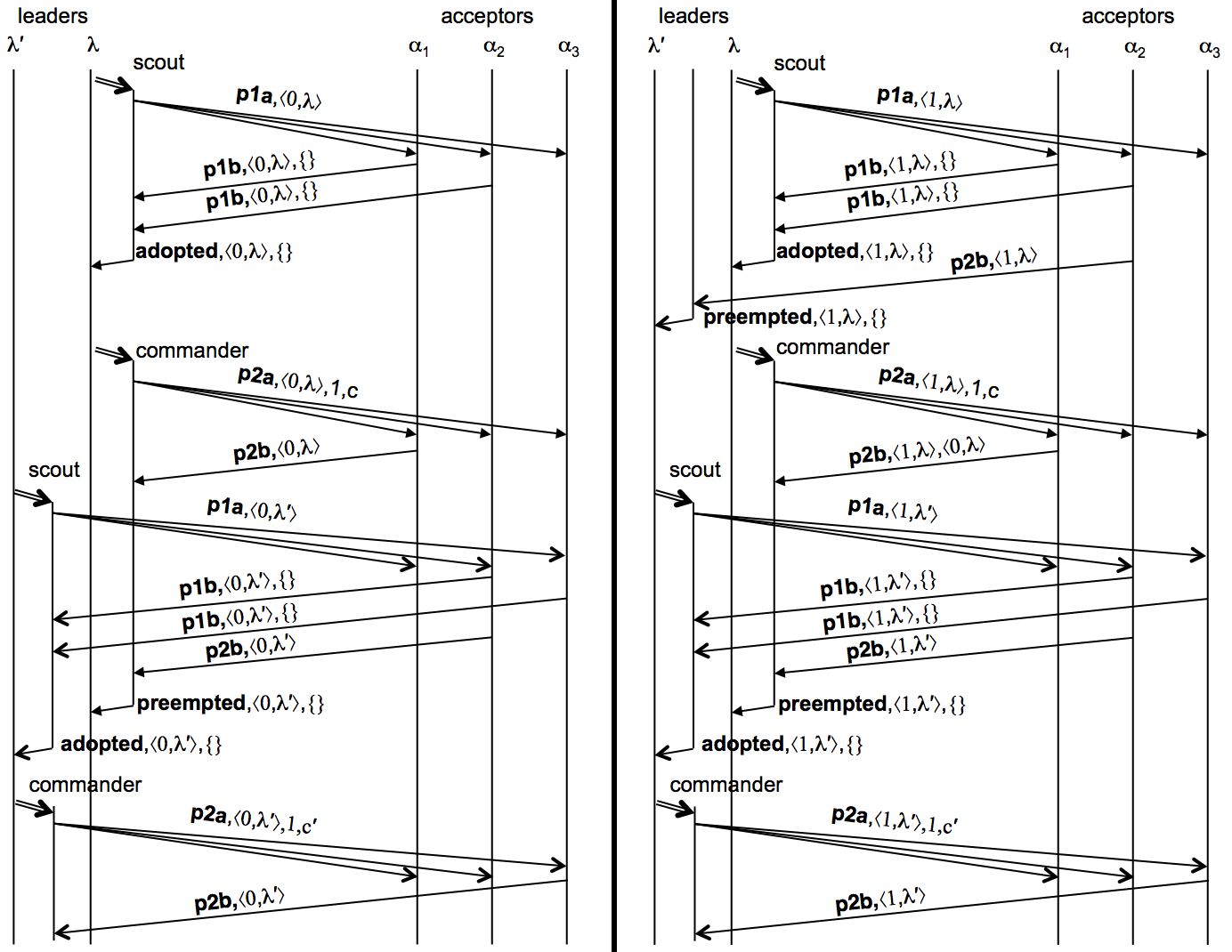
Consider the following scenario shown above, with two leaders with identifiers λ and λ′ such that λ<λ′. Both start at the same time, respectively proposing commands c and c′ for slot number 1. Suppose there are three acceptors, α1, α2, and α3. In ballot ⟨0,λ⟩, leader λ is successful in getting α1 and α2 to adopt the ballot, and α1 to accept pvalue ⟨⟨0,λ⟩,1,c⟩.
Now leader λ′ gets α2 and α3 to adopt ballot ⟨0,λ′⟩, which has a higher ballot number than ballot ⟨0,λ⟩ because λ<λ′. Note that neither α2 or α3 accepted any pvalues, so leader λ′ is free to select any proposal. Leader λ′ then gets α3 to accept ⟨⟨0,λ′⟩,1,c′⟩.
At this point, acceptors α2 and α3 are unable to accept ⟨⟨0,λ⟩,1,c⟩ and thus leader λ is unable to get a majority of acceptors to accept ⟨⟨0,λ⟩,1,c⟩. Trying again with a higher ballot, leader λ gets α1 and α2 to adopt ⟨1,λ⟩. The maximum pvalue accepted by α1 and α2 is ⟨⟨0,λ⟩,1,c⟩, and thus λ must propose c. Suppose λ gets α1 to accept ⟨⟨1,λ⟩,1,c⟩. Because acceptors α1 and α2 adopted ⟨1,λ⟩, they are unable to accept ⟨⟨0,λ′⟩,1,c′⟩. Trying to make progress, leader λ′ gets α2 and α3 to adopt ⟨1,λ′⟩, and gets α3 to accept ⟨⟨1,λ′⟩,1,c′⟩.
This ping-pong scenario can be continued indefinitely, with no ballot ever succeeding in choosing a pvalue. This is true even if c=c′, that is, the leaders propose the same command. The well-known ‘‘FLP impossibility result’’ demonstrates that in an asynchronous environment that admits crash failures, no consensus protocol can guarantee termination, and the Synod protocol is no exception. The argument does not apply directly if transitions have non-deterministic actions—for example changing state in a randomized manner. However, it can be demonstrated that such protocols cannot guarantee a decision either.
If we could somehow guarantee that some leader would be able to work long enough to get a majority of acceptors to adopt a high ballot and also accept a pvalue, then Paxos would be guaranteed to choose a proposed command. A possible approach could be as follows: when a leader λ discovers, through a 𝚙𝚛𝚎𝚎𝚖𝚙𝚝𝚎𝚍 message, that there is a higher ballot with leader λ′ active, rather than starting a new scout with an even higher ballot number, λ starts monitoring λ′ by pinging it on a regular basis. As long as λ′ responds timely to pings, λ waits patiently. Only if λ′ stops responding will λ select a higher ballot number and start a scout.
This concept is called failure detection, and theoreticians have been interested in the weakest properties failure detection should have in order to support a consensus algorithm that is guaranteed to terminate. In a purely asynchronous environment, it is impossible to determine through pinging or any other method whether a particular leader has crashed or is simply slow. However, under fairly weak assumptions about timing, we can design a version of Paxos that is guaranteed to choose a proposal. In particular, we will assume that both the following are bounded:
the clock drift of a process, that is, the rate of its clock is within some factor of the rate of real-time; the time between when a non-faulty process initiates sending a message, and the message having been received and handled by a non-faulty destination process. We do not need to assume that we know what those bounds are—only that such bounds exist. From a practical point of view, this seems entirely reasonable. Modern clocks progress certainly within a factor of 2 of real-time. A message between two non-faulty processes is likely delivered and processed within, say, a year. Even if the network was partitioned at the time the sender started sending the message, by the time a year has expired the message is highly likely to have been delivered and processed.
These assumptions can be exploited as follows: we use a scheme similar to the one described above, based on pinging and timeouts, but the value of the timeout interval depends on the ballot number: the higher the competing ballot number, the longer a leader waits before trying to preempt it with a higher ballot number. Eventually the timeout at each of the leaders becomes so high that some correct leader will always be able to get its proposals chosen.
For good performance, one would like the timeout period to be long enough so that a leader can be successful, but short enough so that the ballots of a faulty leader are preempted quickly. This can be achieved with a TCP-like AIMD (Additive Increase, Multiplicative Decrease) approach for choosing timeouts. The leader associates an initial timeout with each ballot. If a ballot gets preempted, the next ballot uses a timeout that is multiplied by some small factor larger than one. With each chosen proposal, this initial timeout is decreased linearly. Eventually the timeout will become too short, and the ballot will be replaced with another even if its leader is non-faulty.
Liveness can be further improved by keeping state on disk. The Paxos protocol can tolerate a minority of its acceptors failing, and all but one of its replicas and leaders failing. If more than that fail, consistency is still guaranteed, but liveness will be violated. A process that suffers from a power failure but can recover from disk is not theoretically considered crashed—it is simply slow for a while. Only a process that suffers a permanent disk failure would be considered crashed.
For completeness, we note that for liveness we also assumed reliable communication. This assumption can be weakened by using a fair links assumption: if a correct process repeatedly sends a message to another correct process, at least one copy is eventually delivered. Reliable transmission of a message can then be implemented by periodic retransmission until an Ack is received. In order to prevent overload on the network, the time intervals between retransmissions can grow until the load imposed on the network is negligible. The fair links assumption can be weakened further, but such a discussion is outside the scope of this paper.
As an example of how liveness is achieved, a correct client retransmits its request to replicas until it has received a response. Because there are at least f+1 replicas, at least one of those replicas will not fail and will assign a slot to the request and send a proposal to the f+1 or more leaders. Thus at least one correct leader will try to get a command decided for that slot. Should a competing command get decided, the replica will reassign the request to a new slot and retry. While this may lead to starvation, in the absence of new requests, any outstanding request will eventually get decided in at least one slot.